Using browser models
eventcatalog@2.24.2EventCatalog Chat has two types of models, browser based and server based.
- Browser based models: These models run in your browser. This uses WebLLM
- Server based models: These models are run on the server. You provide your own keys and models. We currently support OpenAI models.
How does browser based models work?
Browser based models use a local-first approach to keep your data secure and local. Models are downloaded to your browser, and your catalog is used as a source of reference. The model will use vector embeddings to find the most relevant information in your catalog.
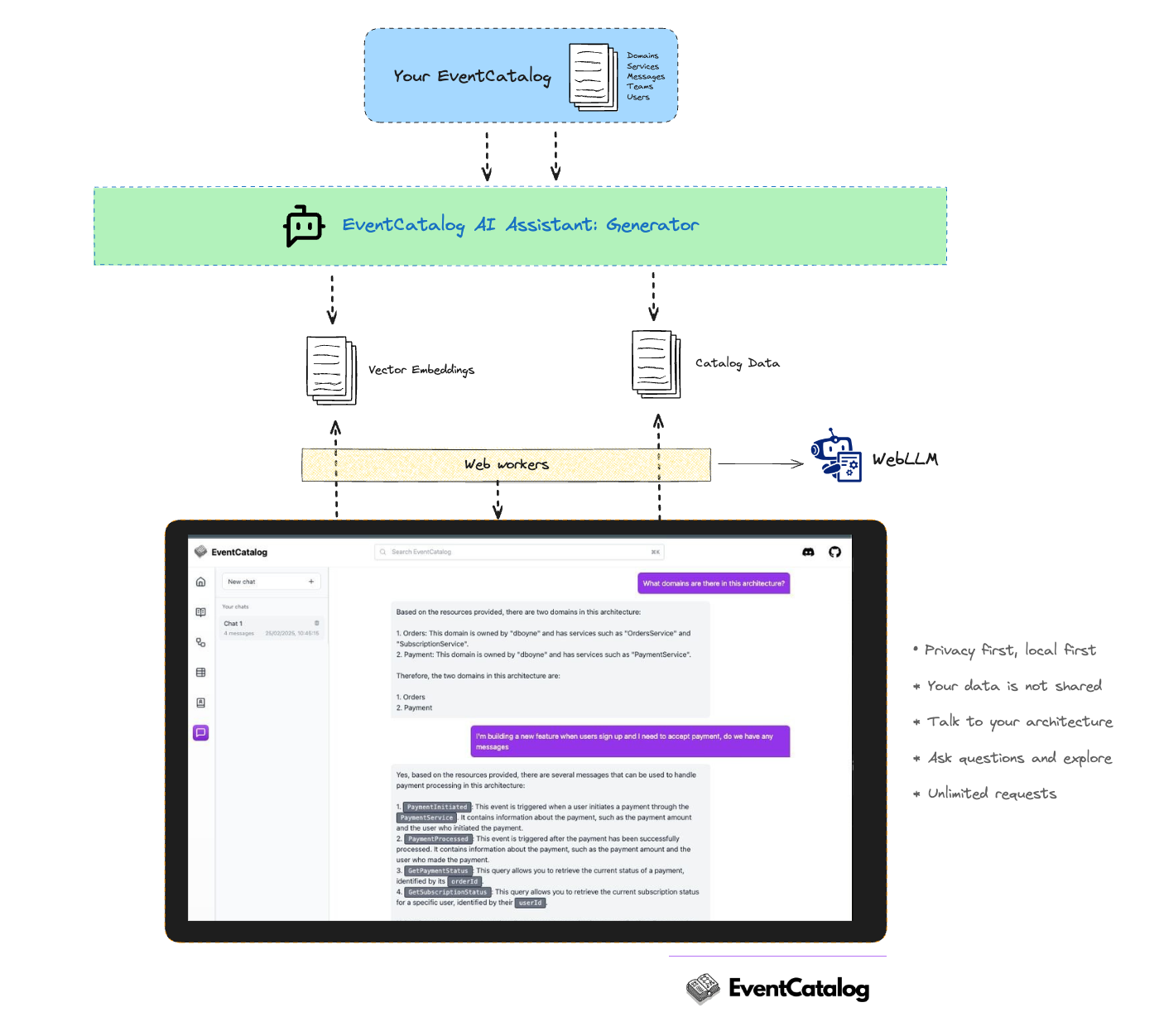
Installation
Setup your license key
EventCatalog Chat is a paid feature, you can get a 14 day free trial of the EventCatalog Starter Plan on EventCatalog Cloud.
Once you have a license key, you can put it into your .env file.
EVENTCATALOG_LICENSE_KEY=<your-license-key>
This will enable the chat in your catalog.
Install the @eventcatalog/generator-ai plugin
Install the @eventcatalog/generator-ai plugin in your catalog directory.
npm install @eventcatalog/generator-ai
Next, configure the plugin in your eventcatalog.config.js file.
// rest of file
generators: [
[
"@eventcatalog/generator-ai", {
// optional, if you want to split markdown files into smaller chunks
// Can help with your models (default false)
splitMarkdownFiles: true,
// optional, if you want to include users and teams in the documents (embeddings)
// default is false, better search results without, but if you want the ability to ask questions about users and teams then set to true
includeUsersAndTeams: false,
// optional, if you want to include custom documentation in the documents (embeddings)
// custom documentation is a feature that lets you bring any documentation into EventCatalog
// default is true, but you can turn this off if you don't want to include custom documentation in the documents
includeCustomDocumentation: false,
// optional, if you want to use a different embedding model
// default is huggingface
// added in version @eventcatalog/generator-ai@1.0.2
embedding: {
// Set the provider to huggingface
provider: 'huggingface',
// Set the model to the huggingface model
model: 'Xenova/all-MiniLM-L6-v2',
}
}
],
],
Generate the documents and embeddings for your catalog by running the following command.
npm run generate
This will generate your documents and embeddings for your catalog. The browser model will use these documents and embeddings to answer your questions.
This will create documents and embeddings for your catalog. You need to rerun this command whenever you make changes to your catalog.
Configure the WebLLM model
Next, you need to configure the WebLLM model. Add the following to your eventcatalog.config.js file.
chat: {
// enable the chat or not (default true, for new catalogs)
enabled: true,
// Optional model you can use, default is Hermes-3-Llama-3.2-3B-q4f16_1-MLC
// Another good one is Llama-3.2-3B-Instruct-q4f16_1-MLC
model: 'Hermes-3-Llama-3.2-3B-q4f16_1-MLC',
// The maximum number of tokens to generate in the completion (4096 by default, value from model)
max_tokens: 4096,
// number of results to match in the vector search (50 by default)
similarityResults: 50
}
Selecting your own model
WebLLM supports a wide range of models, you can find the list of supported models in the models section.
Run EventCatalog
Once you have installed and configured the plugin, and enabled the chat in the eventcatalog.config.js file, you can run the catalog.
npm run generate
npm run dev
Navigate to the http://localhost:3000/chat and you should see the AI assistant.
If you want to see a demo of the AI assistant, you can try our demo catalog here.
Configuration
Models
Through testing we found these two models work well (small, fast and give good results):
But feel free to experiment with other models and parameters to find the best model for your catalog.
Configuring your model
To configure your model, you need to update the eventcatalog.config.js file.
// rest of the config...
chat: {
enabled: true,
// model value, default is Hermes-3-Llama-3.2-3B-q4f16_1-MLC
model: 'Hermes-3-Llama-3.2-3B-q4f16_1-MLC',
// max tokens for your model (default 4096)
max_tokens: 4096,
// number of results to match in the vector search (50 by default)
similarityResults: 50
}
Some models are larger than others and may take longer to load, smaller models may be less accurate, but you have the freedom to experiment with the best model for your catalog.
List of models for EventCatalog
Models vary in size and performance, we recommend you to experiment with the best model for your catalog.
Smaller models are faster but may be less accurate, but larger models are more accurate but may be slower to download and load.
DeepSeek
- DeepSeek R1 Distill Qwen 7B (q4f16)
- model value:
DeepSeek-R1-Distill-Qwen-7B-q4f16_1-MLC
- model value:
- DeepSeek R1 Distill Qwen 7B (q4f32)
- model value:
DeepSeek-R1-Distill-Qwen-7B-q4f32_1-MLC
- model value:
- DeepSeek R1 Distill Llama 8B (q4f16)
- model value:
DeepSeek-R1-Distill-Llama-8B-q4f16_1-MLC
- model value:
- DeepSeek R1 Distill Llama 8B (q4f32)
- model value:
DeepSeek-R1-Distill-Llama-8B-q4f32_1-MLC
- model value:
Llama (Meta)
- Tiny Llama 1.1B - (1k)
- model value:
TinyLlama-1.1B-Chat-v0.4-q4f32_1-MLC-1k
- model value:
- Llama-2-7b-chat-hf-q4f16_1-MLC
- model value:
Llama-2-7b-chat-hf-q4f16_1-MLC
- model value:
- Llama-2-7b-chat-hf-q4f32_1-MLC-1k
- model value:
Llama-2-7b-chat-hf-q4f32_1-MLC-1k
- model value:
- Llama-2-13b-chat-hf-q4f16_1-MLC
- model value:
Llama-2-13b-chat-hf-q4f16_1-MLC
- model value:
- Llama-3-8B-Instruct-q4f16_1-MLC
- model value:
Llama-3-8B-Instruct-q4f16_1-MLC
- model value:
- Llama-3-8B-Instruct-q4f32_1-MLC-1k
- model value:
Llama-3-8B-Instruct-q4f32_1-MLC-1k
- model value:
- Llama-3-70B-Instruct-q3f16_1-MLC
- model value:
Llama-3-70B-Instruct-q3f16_1-MLC
- model value:
Gemma (Google)
- Gemma 2B
- model value:
gemma-2b-it-q4f32_1-MLC
- model value:
- Gemma2 2B
- model value:
gemma-2-2b-it-q4f32_1-MLC
- model value:
- Gemma2 2B - (1k)
- model value:
gemma-2-2b-it-q4f32_1-MLC-1k
- model value:
- Gemma2 9B
- model value:
gemma-2-9b-it-q4f32_1-MLC
- model value:
- Gemma2 9B - (1k)
- model value:
gemma-2-9b-it-q4f32_1-MLC-1k
- model value:
Other models
EventCatalog uses WebLLM to load models into your browser. Any model that is supported by WebLLM is supported by EventCatalog. You can find a list of models supported by WebLLM here.
Browser support
EventCatalog Chat using browser models is supported in Chrome and Edge.
By default, WebGPU is enabled and supported in both Chrome and Edge. However, it is possible to enable it in Firefox and Firefox Nightly. Check the browser compatibility for more information.
Hardware requirements
To run the models efficiently, you'll need a GPU with enough memory. 7B models require a GPU with about 6GB memory whilst 3B models require around 3GB.
Smaller models might not be able to process file embeddings as efficient as larger ones.
You can configure which model to use in the eventcatalog.config.js file.
Got a question? Or want to contribute?
Found a good model for your catalog? Please let us know on Discord. Or if you need help configuring your model, please join us on Discord.
Have a question?
If you have any questions, please join us on Discord.