
May was one of our biggest months yet. Agents and ADRs are now first-class resources you can document and govern, the EventCatalog Editor is in beta, plus full-content search, GitHub user sync, and more features aimed at coding agents.
Welcome to the monthly update for EventCatalog. May was one of our biggest months yet, and there was a clear theme running through it: your catalog should be the source of truth for the humans building your system and the AI agents working alongside them.
We made agents and architecture decisions (ADRs) first-class resources, shipped a visual editor in beta, and added full-content search, GitHub user sync, and a set of features aimed squarely at coding agents. Here's everything that landed.
- Document and Govern AI Agents
- Architecture Decision Records
- EventCatalog Editor (Beta)
- Full-content search
- Sync users and teams from GitHub
- Docs your AI agents can trust
- Prompt and Visibility components
- API catalog discovery
- Flows reach the data layer
- Other project improvements
Document and Govern AI Agents
Most companies are not going to have one agent. They are going to have many. One team adds a support agent, another adds a fraud review agent, another adds an internal architecture assistant. Each one consumes events, calls tools, reads data, and produces work that downstream systems depend on. If an agent influences your system, it needs to be visible in the same place as the rest of your architecture.
EventCatalog 3.41.0 adds agents as a first-class resource. Each agent gets its own page, frontmatter API, sidebar entry, search result, visualizer node, ownership metadata, and version history.
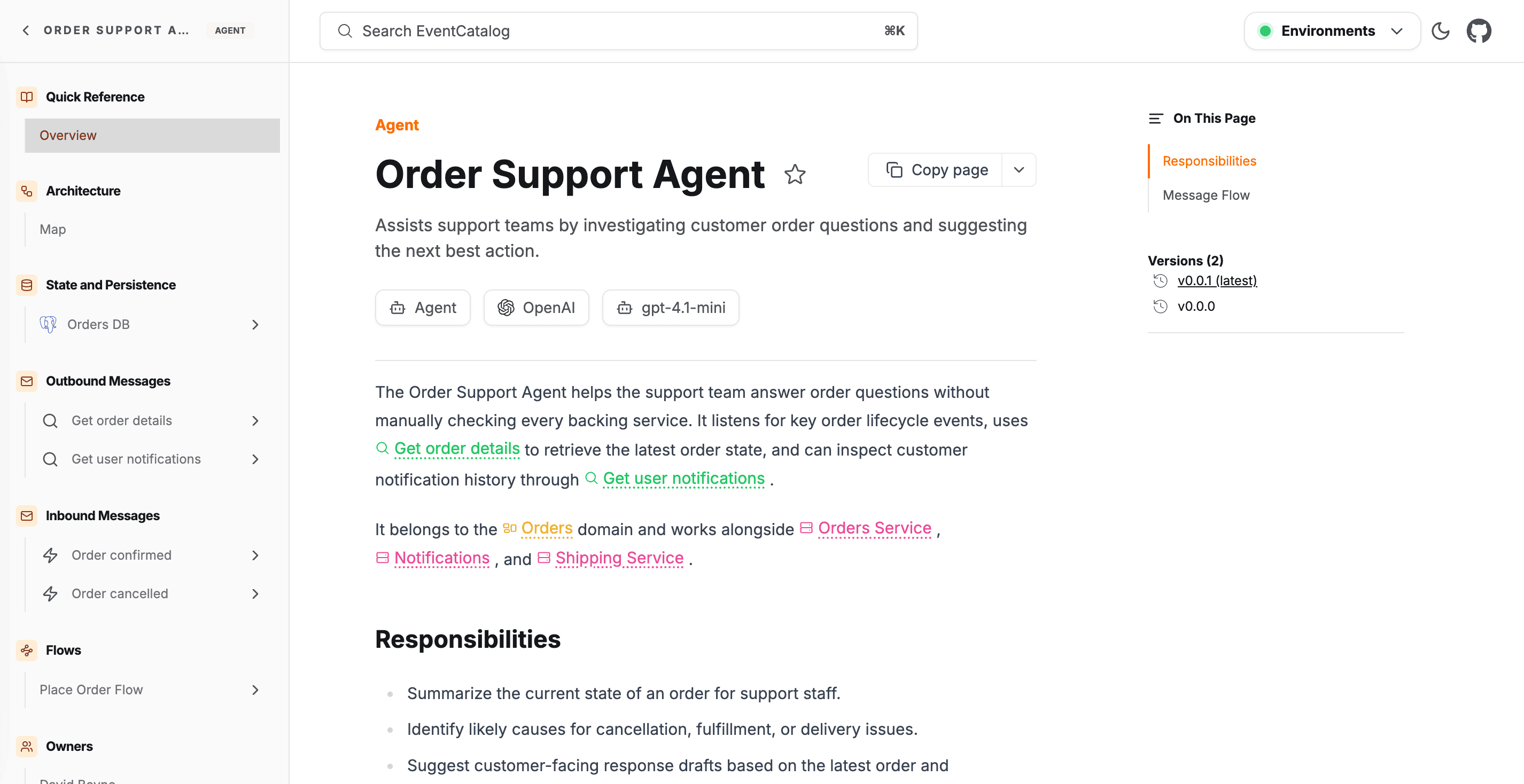
For each agent you can document who owns it, which model it uses, which tools (MCP servers, APIs, databases, search indexes) it can call, which messages it consumes and produces, and which data stores it reads from or writes to. Agents also show up in the visualizer and can be used as nodes in flows, so you can see exactly how information moves between agents, services, messages, and data.
A huge thank you to Martijn van der pauw for raising the original RFC and helping shape this one.
You can read more about agents in our release blog post here.
Architecture Decision Records
Your catalog tells you what services exist, what events they produce, what schemas look like. What it hasn't told you is why any of it was built the way it was. Why Kafka over RabbitMQ. Why the Orders domain owns customer address data. Decisions separated from the things they describe are decisions that get made again, usually with incomplete information.
Architecture Decision Records are now a first-class resource in EventCatalog. They have frontmatter, versioning, and markdown content, and they show up in search, the Discover page, and the visualizer alongside everything else.
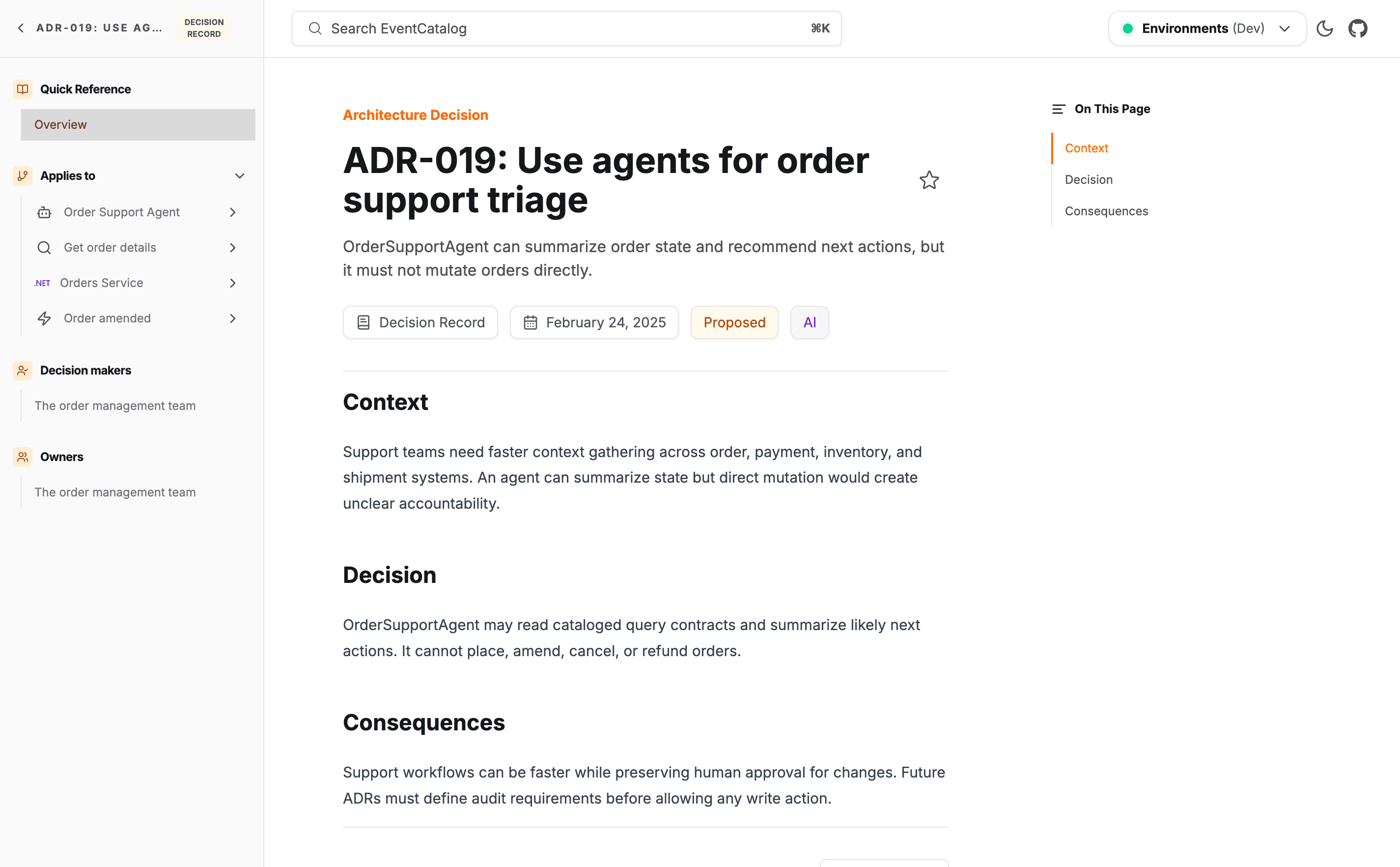
The most useful part is the appliesTo field, which links an ADR directly to the services, events, commands, and domains it governs. Those links are bidirectional, so when someone views OrdersService they see the decisions that shaped it, right at the point where it matters. ADRs also track lineage through supersedes, amends, and related, and because they live in the catalog the MCP server can answer "why did we choose Kafka for the Orders domain?" by reading the actual decision record.
You can read more about ADRs in our release blog post here.
EventCatalog Editor (Beta)
Catalog maintenance is not only an engineering task. Architects, analysts, and product owners often know what needs to change, but the source files, frontmatter, schemas, and Git workflow slow them down.
EventCatalog Editor is now in beta. It gives your team a local visual editor for maintaining the same EventCatalog files you already keep in Git. You can edit resources, preview changes, review diffs, and publish local commits without opening Markdown for every update.
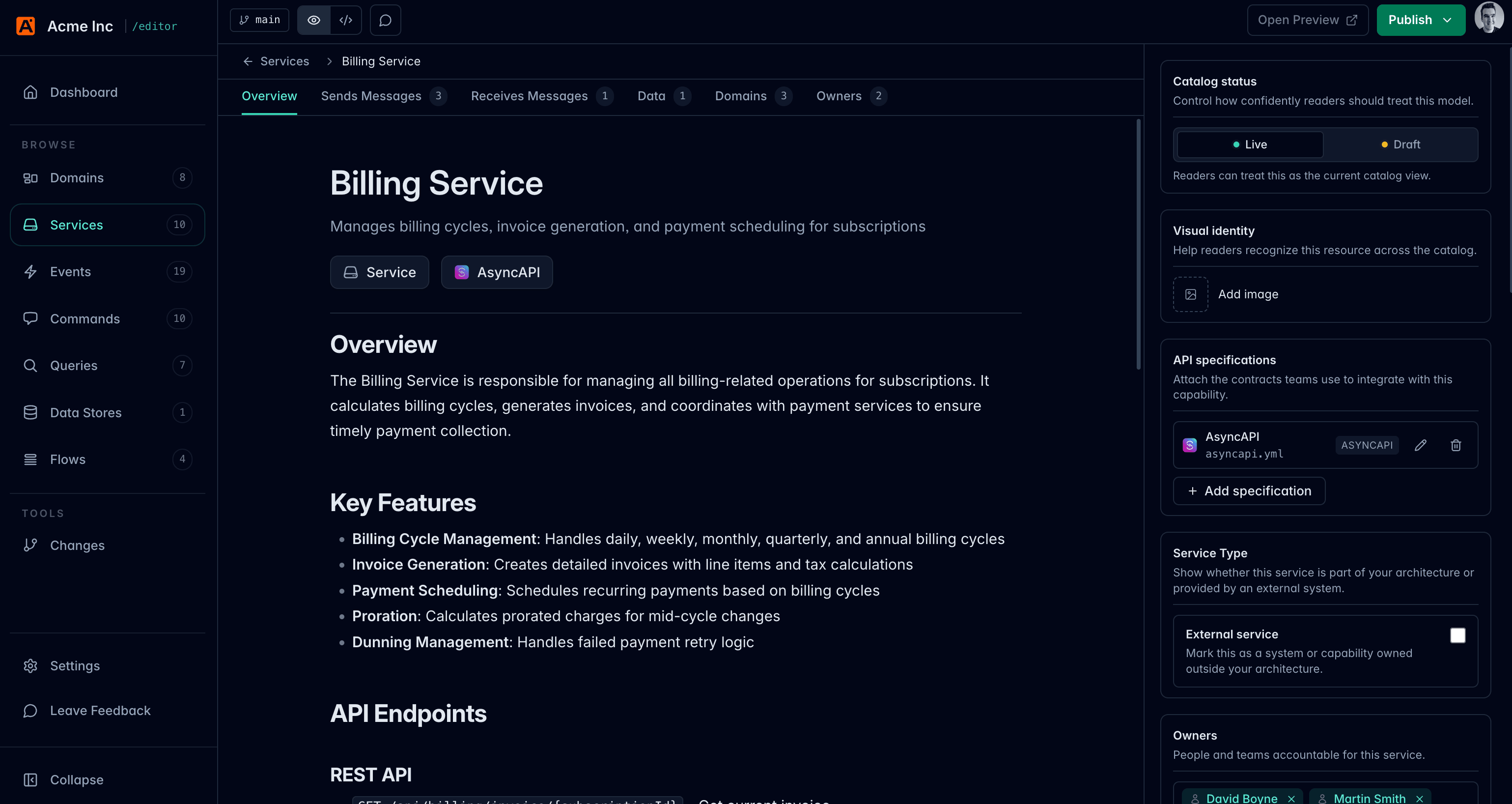
The editor runs locally on top of your catalog and writes changes back to the same files, so your existing review and release process stays in place. Highlights include a visual Flow Editor for building flows by shape rather than YAML, a changes view that groups local Git diffs by resource before you publish, and slash commands for inserting diagrams, callouts, prompts, and resource-aware blocks without remembering the syntax. Source mode is always one click away when you need it.
You can read more about the Editor in our release blog post here.
Full-content search
The default search is fast and works everywhere, but it only sees frontmatter-level data: names, identifiers, types, summaries, and badges. If the detail you need is buried in a message payload description, a changelog entry, or a custom architecture doc, the default search will not find it.
EventCatalog v3.36.0 adds indexed full-content search. It reads the body of every page in your catalog, powered by Pagefind. If a term appears anywhere in your documentation, it shows up.
Enabling it is one line in your eventcatalog.config.js:
// eventcatalog.config.js
// ... rest of your config
search: {
type: 'indexed',
},
};
The index builds automatically during eventcatalog build and eventcatalog dev, with debounced rebuilds whenever a .md or .mdx file changes. Results are ranked so titles and identifiers score highest, then summaries, then body content. One note for auth-protected catalogs: Pagefind stores full page content in a /pagefind directory, so protect it with the same auth layer as your pages.
You can read more about indexed search in our release blog post here.
Sync users and teams from GitHub
Teams and users are how you assign ownership in EventCatalog, and ownership is only useful when it is accurate. Keeping a list current by hand is not sustainable. People join and leave teams, teams get restructured, and the catalog falls behind until nobody trusts the data.
EventCatalog can now sync users and teams directly from GitHub. Point the new githubDirectory connector at your org, list the teams you care about, and ownership data stays accurate automatically.
flowchart LR
GH[GitHub org] --> C[GitHub connector]
C --> EC[EventCatalog]
EC --> U[Users & Teams]
If your team data lives somewhere else, an HR tool, LDAP, Okta, or Microsoft Entra, you can build your own connector with defineDirectorySource. The same sync mechanism runs regardless of the source. Directory sync is a Scale plan feature (and available on Enterprise), but the connector package is open source so you can build and test locally.
You can read more about GitHub sync in our release blog post here.
Docs your AI agents can trust
I've been using Claude Code and Cursor every day on EventCatalog, and I kept hitting the same thing: the agent would confidently spit out frontmatter that didn't exist or point at folders we'd renamed months ago. It's not really the agent's fault, it's working from a snapshot of the web that's months out of date, and EventCatalog moves fast.
As of 3.35.1, the full EventCatalog docs are bundled inside the npm package, version-matched to whatever you have installed. After a normal install they live at node_modules/@eventcatalog/core/dist/docs/. No extra install, no network request, no version mismatch. New projects scaffolded with create-eventcatalog get an AGENTS.md and CLAUDE.md that tell any coding agent to read those docs before generating anything.
You can read more about bundled docs in our release blog post here.
Prompt and Visibility components
Writing docs that serve both a human reading the UI and an AI agent consuming raw markdown used to mean maintaining two versions of the same information. That overhead compounds fast across a large catalog.
EventCatalog 3.33.0 ships two new MDX components to fix this:
- `` embeds a copyable AI prompt block directly on any resource page, with one-click copy to clipboard or open in Cursor.
<Visibility>gates content by audience in a single file. Humans see one block in the UI, AI agents see another in the raw markdown. The same file, zero duplication, two audiences.

You can read more about both components in our release blog post here.
API catalog discovery
Developers and agents should not need to crawl your docs site to find the contracts your team already publishes. They should be able to ask one known URL and get a machine-readable answer.
EventCatalog can now publish an API catalog at /.well-known/api-catalog, following RFC 9727. The endpoint returns a Linkset of every service and domain with OpenAPI, AsyncAPI, or GraphQL specifications attached, plus the EventCatalog MCP endpoint when enabled. Your catalog already knows where your APIs live, this exposes that knowledge in a format developer tools and agents can consume directly.
You can read more about API catalog discovery in our release blog post here.
Flows reach the data layer
Flows let you document end-to-end business workflows across services, messages, actors, and external systems. Until now they stopped at the application layer and went silent the moment data landed somewhere or fed into a report.
v3.36.3 adds two new flow node types, container and dataProduct, so your flows can reach into the data layer. A container step references a data store, and a dataProduct step references a data product. You can now draw the complete picture in a single diagram: the services that process events, the data stores they write to, and the data products built on top.
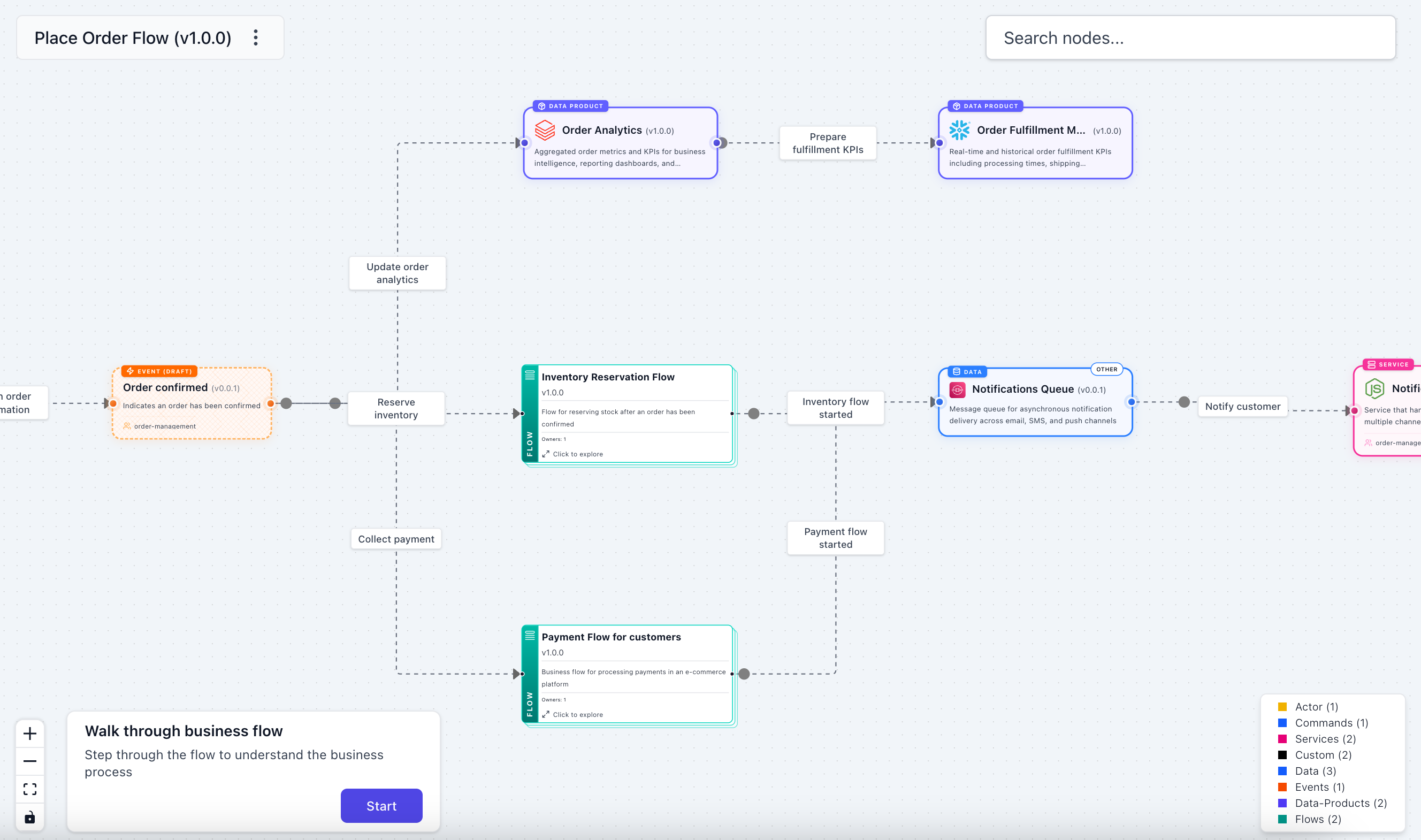
Bidirectional linking is automatic. When a flow references a container or data product, that resource's sidebar gains a "Flows" section listing every flow that touches it.
You can read more about the new flow nodes in our release blog post here.
Other project improvements
- Added search configuration so you can customize what the search modal indexes (search docs)
- `` component renders the tools an agent can call directly on its page
- Slash commands in the Editor for inserting diagrams, callouts, steps, tiles, and prompts
- ADR
statusfield tracks the full lifecycle:proposed,accepted,deprecated,superseded - Auth support added to the EventCatalog Editor for Cloud seats
- New
@eventcatalog/connectorspackage for syncing directory data from external systems
What's coming in June?
A few things we're working on:
- Continued polish on the EventCatalog Editor as we move it through beta toward general availability
- More ways to document and govern AI agents as the resource type matures
- Deeper AI-native workflows building on bundled docs, the MCP server, and skills
If you have any questions or want to join our community of over 1,200 people exploring EventCatalog and event-driven architecture feel free to join us!
Until next time!, Dave